
While the pandemic has necessitated an acceleration for non-Covid clinical trials (reduced by almost 57% during 2020-21), it has also meant that Sponsors/ Institutions must find an innovative, yet compliant, way of running them. Moreover, the number of complex trials is set to increase, so the time taken to identify the rightful patient cohort is bound to increase. Already, cancer.gov states that it may take almost 2 hours to manually screen a patient for cancer trials. No wonder then that Global data reports that with digital trials set to increase by 28% during 2022, it will require digital ways to screen and engage with the patients. Tools like Circlebase’s Automated Clinical Trial Matching (ACTM) can digitize the recruitment process by analyzing complex inclusion and exclusion criteria and creating a patient cohort based on all the relevant information in the medical record.
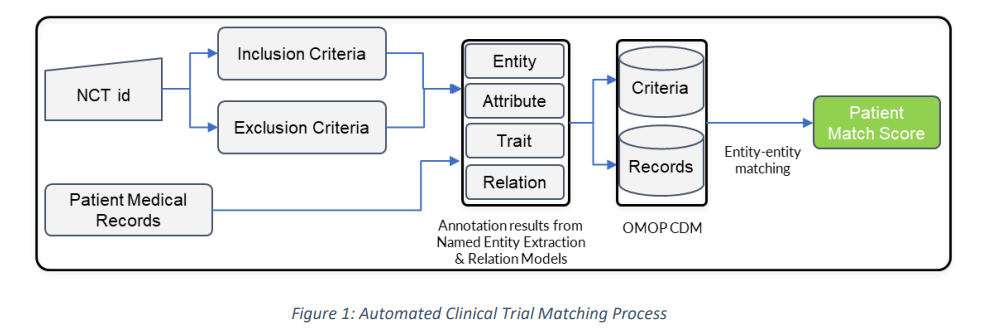
How automation works
1. Annotation of the “Eligibility criteria” stated in the clinical trials
2. Annotation of the medical record of the available patient cohort
3. Match or closeness of fit between the annotations
2. How accurately can the deep learning models recall the pattern for extracting entities and their underlying relationships?
3. How effectively can the entities fuzzy match
The Named Entity Extraction & Relationship Model
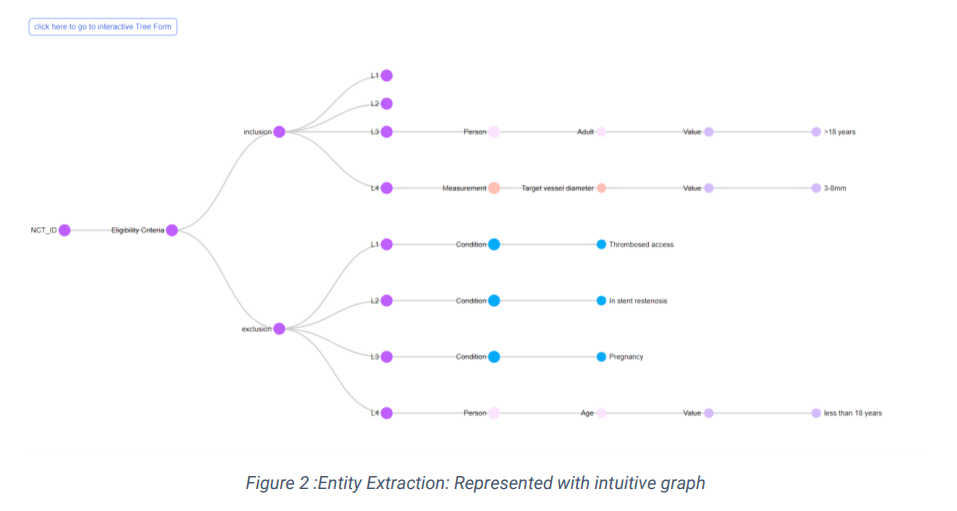
Entity Matching Algorithms
Entities need to be standardized for them to be compared. Hence, they are linked to clinical terminologies like SNOMED CT, ICD 10, RxNorm, and LOINC and then compared. Still, there could be several clinical entities that might fail to match, even if clinically equivalent. An example could be “ductal carcinoma (Concept ID: C0007124)” versus “malignant neoplasm of breast (Concept ID: C0006826)” which may not match directly. This calls for an innovative approach to establishing the match. At Circlebase, our patent-ready algorithm, besides learning from the patterns, utilizes a smarter way to match the entities. This reduces our “miss-rate” and generates high-quality, reliable patient cohorts. Additionally, the algorithm also enables Study teams to see the gaps in their information collection process, thereby helping to streamline the process.
Getting ready for the automation
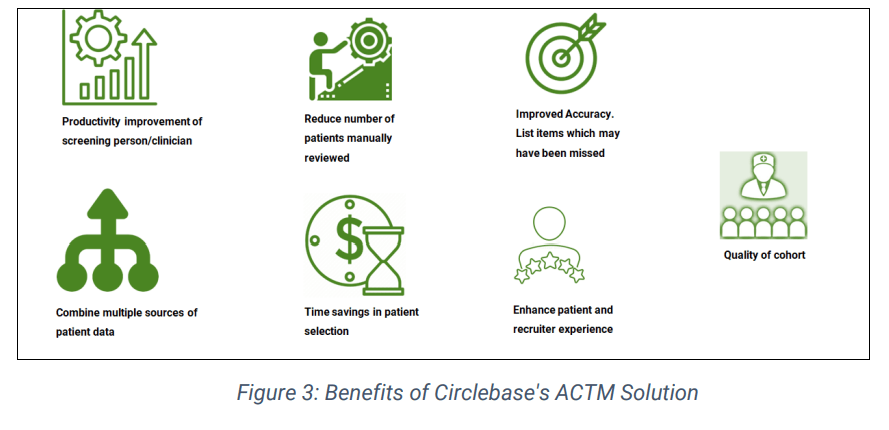
We believe that an ACTM can eventually lead to improved clinical research and patient care and is a logical first step in streamlining digital trials. Circlebase, through its proprietary models and innovative algorithms, provides its clients with a thoroughly tested tool to embark on this automation journey. How have you been screening patients for trials? And how has automation helped you recently? We will be keen to hear from you and share our experiences. Please do write to us at: wecanhelp@circlebase.com